
In the world of computer vision, the human body is found to be one of the most unpredictable elements of any scene. Its unpredictability in terms of how it moves, how it looks from different angles and poses, and how it changes over time is a problem that has plagued the world of computer vision and AI since its inception. How do you get machines to understand human motion when there are so many variables involved? The answer to this question lies in the field of human pose estimation. This is an area of computer vision that deals with identifying and predicting the position and orientation of a human body within a given image or video frame.
Human pose estimation is a subset of the larger field of computer vision and machine learning. It’s the process by which machines are able to identify what a person is doing in any given scene. This can include things like detecting whether someone is walking, running, jumping, or even dancing. Given the rapid evolution of technology solutions and their applications in real-world scenarios, the advancement of human pose estimation promises significant impact in a wide variety of industries from gaming, motion capture (think Avatar!), and athlete training to AI-powered physical trainers and autonomous driving. In this guide, we aim to cover the basic as well as advanced aspects of the history, science, technicalities, applications, and possible future of human pose estimation.
What is Human Pose Estimation?
Human pose estimation is the science of identifying where all of a person’s body parts are in relation to one another and the environment around them. It provides machines with the ability to better understand human behavior, and it’s essential for solving a wide variety of problems in computer vision. Pose estimation can be used to improve many tasks, such as face recognition, body tracking, and gesture recognition. It has also been used for motion capture and motion analysis applications applied to robotics research.
In its most nascent form, Human Pose Estimation (HPE) is a process of identifying and classifying the joints in a human body and determining if the connections between these joints are valid.
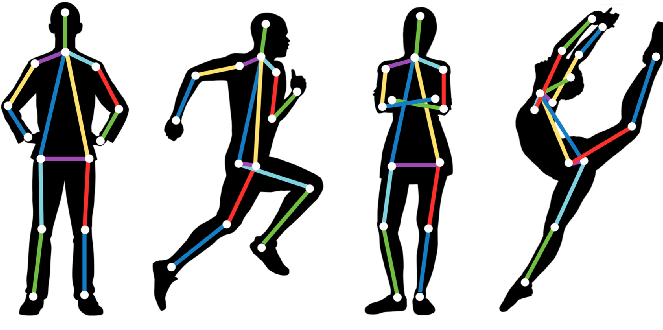
In essence, it is a process of identifying key points and valid pairs. A key point is a coordinate (2D or 3D) describing the location of an anatomical joint that can be used to describe a pose. These points connect to form pairs, each valid connection becoming a pair.
The connection formed between points should be meaningful, which means that any two random points cannot form a pair. Thus the aim of HPE is to arrive at a skeleton-like representation of the human body and then utilize the structure to process the understanding of the human body for specific applications.
Types of Human Pose Estimation Models
Though it is often the first step, identifying key points and pairs is not the only method used for HPE. There are three distinct methods namely –
Skeleton-based Model
Also called the kinematic model, this representation includes a set of key points (joints) like ankles, knees, shoulders, elbows, and wrists that are primarily used for 2D or 3D pose estimation. This flexible, intuitive human body model comprises the skeletal structure of the human body. This model is frequently used to capture relationships between different parts of the anatomy.
Contour-based Model
Also referred to as the planar model, this technique provides 2D pose estimation. The output consists of a rough outline and dimensions for the body, torso, and limbs. It is a visual representation of the body, where the person’s contours are represented by rectangles and boundaries. An example is Active Shape Modeling (ASM) which captures the entire human body, including its shape and silhouette deformations employing principal component analysis (PCA).
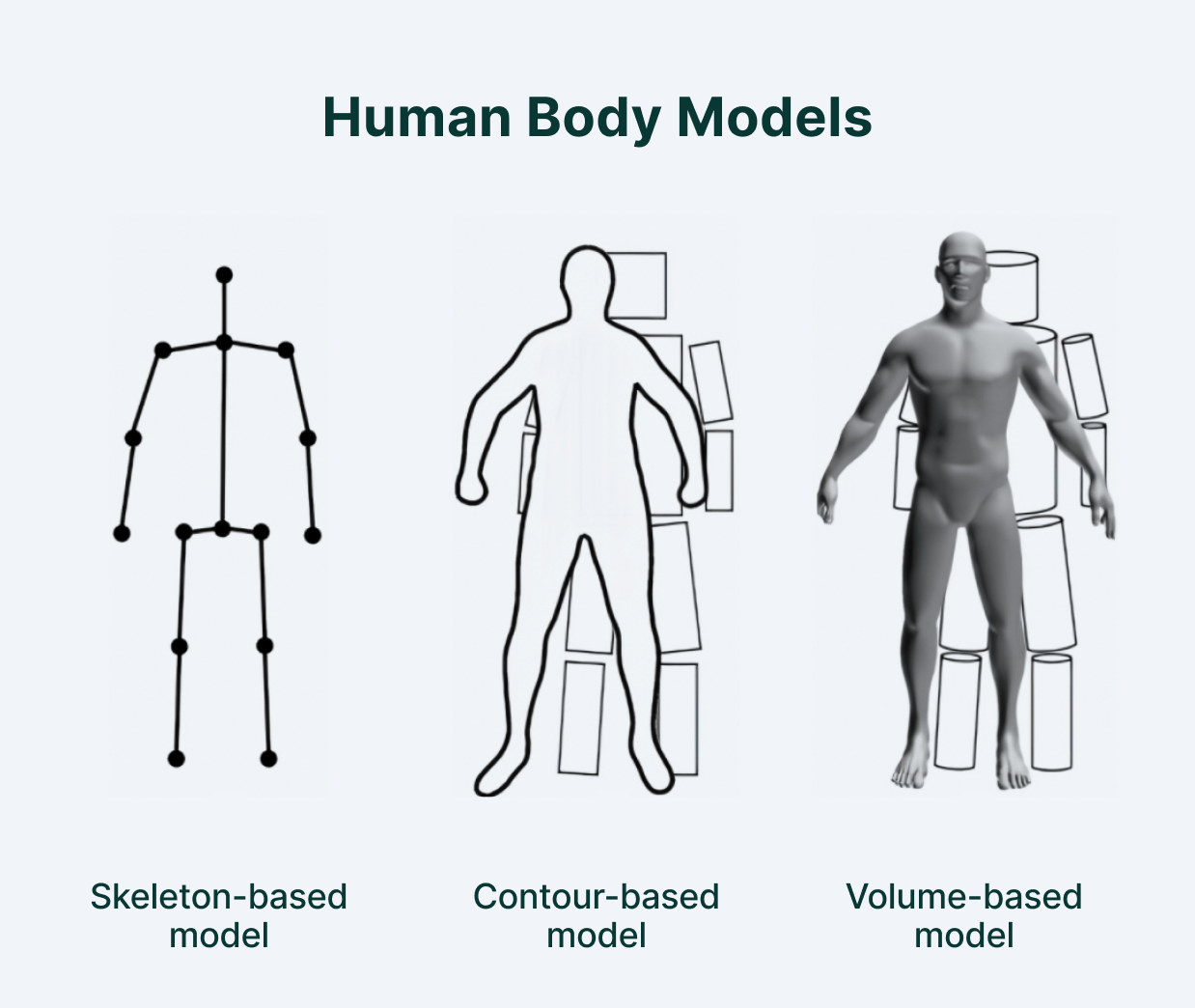
Volume-based Model
A volumetric model provides relevant information for 3D pose estimation. The dataset consists of multiple human body models and poses in 3D space, represented by meshes and shapes. These shapes are generated for 3D pose estimation based on deep learning techniques.
Importance of Human Pose Estimation
Human pose estimation is a very challenging task, and there are many factors that contribute to this. The first issue is that humans can perform an infinite number of movements which makes it difficult for computers to distinguish between them all. For example, there are hundreds of different ways you could bend over and touch your toes! Another challenge is that the human body has a large degree of variability in its appearance from person to person; this makes it difficult for machines to understand and predict human movement.
The first human pose estimation algorithm was developed in the late 1990s, but it wasn’t until recently that computer vision researchers were able to apply machine learning methods to tackle this problem. For many years, people detection has been a primary focus of discussion for object detection applications. With recent advances in machine-learning algorithms, computers can now recognize human body language by detecting and tracking human posture. Improved performance and accuracy of hardware technology have made it commercially viable to utilize human pose estimation for a variety of real-world applications. Human pose estimation has begun to significantly impact a variety of industries, from security, defense, and business intelligence, to gaming, entertainment, and health.
For example, the use of real-time human pose detection and tracking has helped computers to predict pedestrian behavior more consistently—a development that is vital for the autonomous driving industry.
Human Pose Estimation in the Real World
As a technology application, HPE can be considered quite mature since there are already signs of cutting-edge solutions in the areas of fitness, rehabilitation, physiotherapy, motion capture, advanced gaming, robotics, and surveillance.

AI-Powered Personal Trainers
Body-pose estimation is a technology that opens up new possibilities for fitness apps and AI-driven coaching. The application can use a hand-held device such as a phone camera to record the movement of the user and based on a model analyze the quality of movement to provide feedback and guidance to the user. Tracking the real-time movement is done via tracking the key points and providing analytics in the form of hints or graphic analysis. This can be handled in real-time, providing instant feedback to the user about his or her major movement patterns and body mechanics.
One shining example of the use of HPE is Kemtai’s Motion Intelligence Platform, which connects the user to an entire ecosystem of exercise tools. Using artificial intelligence and advanced computer vision to analyze human motion and provide real-time training feedback, Kemtai delivers exercises for physiotherapy and fitness.. By providing a personalized home-fitness gym with training feedback on a browser, without the need for any accessories or expensive fitness devices, Kemtai’s Technology might removed unnecessary complexity from fitness and physical therapy. Taking a step ahead, Kemtai’s proprietary Motion Tracking technology can be easily coupled with existing fitness offerings that could boost the technological value of the offering. Partners can use Kemtai’s workouts in their applications, creating a one-of-a-kind experience for customers to enjoy at home.
Rehabilitation and Physiotherapy
The physiotherapy industry is another domain where human pose estimation has made a mark. Remote physiotherapy is a growing industry. It’s one of the most promising applications for pose estimation AI in the healthcare sector. In the digital era, at-home digital consultations improve flexibility and accessibility for the patient and productivity for the therapist. AI technologies have enabled new and more complex ways to deliver treatment digitally.
AI-guided home exercising, employing HPE can provide a level of care that is on par with or even better than having a physiotherapist visit the patient at home and guide them through the correct motions. Musculoskeletal physiotherapy exercises play a key role in rehabilitation and recovery from MSK issues. Real-time feedback, corrective guidance, and overall tracking of the patient’s recovery increase the impact of digital physiotherapy exercises and make remote physical therapy substantially more effective, both for the patient and the therapist.
Motion capture and augmented reality
In addition to its use in the real world, human pose estimation has been incorporated into virtual reality and augmented reality experiences such as games or movies for motion capture purposes. The use of human pose estimation in AR and VR allows for more natural interaction with the virtual environment, avoiding the “uncanny valley” effect. This is especially true for VR applications where users may be interacting with objects using their hands or body movements, for example playing tennis or test driving a new car virtually. Motion tracking in VR can be challenging due to the lack of reference points available, but the use of human pose estimation algorithms can help overcome this obstacle by providing accurate data about where objects are located in relation to one another. This makes real-world use cases such as virtual trial rooms for clothing and fashion or glasses and shoes a realistic experience, boosting the novelty of fashion and consumer brands.
Motion capture technology has been utilized to train robots for different activities. AI pose estimation is today used to teach robots certain crafts. Robots can be taught to execute actions by copying a human’s posture and trajectory of movement rather than being programmed manually.
Athlete pose detection
Today, almost all sports are heavily reliant on data analysis. Pose detection helps players improve their technique and achieve better results. It also allows athletes to analyze the strengths and weaknesses of their opponents—which is invaluable for professional sportsmen and trainers.
How does Human Pose Estimation Work?
Pose estimation uses the pose and orientation of a person or object to track its location. It provides programs with the capability to estimate spatial positions or poses of a body in a static image or in a video. In general, most pose estimators are two-step processes: First they detect human bounding boxes and then estimate the poses within each box. Pose estimation works by locating key points of a person or object. Single-pose estimation is used for estimating poses for a single object in a given scene, while multi-pose estimation is used when detecting poses from multiple objects.
Several approaches have been proposed for solving the problem of estimating human poses. However, existing methods can be broadly categorized into three groups: absolute pose estimation, relative pose estimation, and appropriate-pose estimation.
Absolute pose estimation method is powered by satellite-based navigation signals and heatmap matching, it can take its cues from a variety of active and passive landmarks. Relative pose estimation is based on a method known as dead reckoning, which computes the pose of humans by estimating their distance from known joints such as initial position and orientation. Appropriate pose estimation is a mixture of absolute and relative methods.
Model Architecture Overview
Human pose estimation models come in a few varieties involving bottom-up or top-down approaches. In bottom-up methods, the body joints are first examined one by one and then arranged to form a unique pose. A top-down approach runs a body detector first and demarcates the bounding boxes for each body before determining the body joints within the bounding boxes.
Since the advent of deep learning techniques, the science of HPE has employed deep learning models to evaluate and understand human posture. As the research and development at HPE took off, new challenges were encountered. Multi-person pose estimation was one such problem.
Deep Neural Networks (DNNs) are adept at estimating the pose of a single human but struggle to accurately do so when multiple humans or objects are present, since
- An image can contain multiple people, each in a different position and posture.
- Computational complexities increase with the number of people since there could be many interactions.
- Increased computation complexity increases inference time in real time.
This is where the two approaches – top-down and bottom-up are employed to solve for multi-person pose estimation.
OpenPose
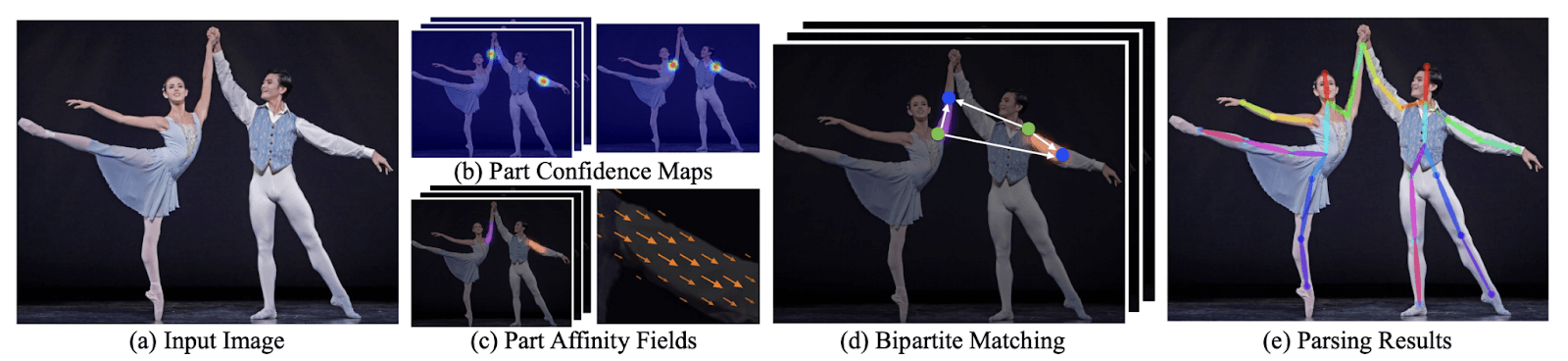
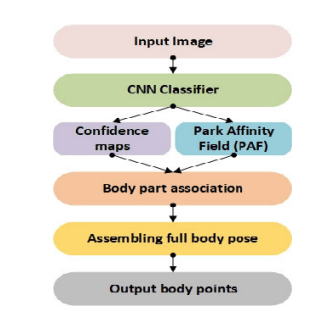
Proposed by Zhe Cao and others in 2019, OpenPose is a bottom-up approach. It uses a Convolutional neural network as its main architecture. It relies on a VGG-19 convolutional network to extract patterns and representations from input images. The VGG-19 output is broadcast to two convolutional networks.
The first network predicts a set of confidence values for each body part, while the second branch creates a part affinity field—a measure of association between parts. It also prunes weaker links in bipartite graph structures like this one.
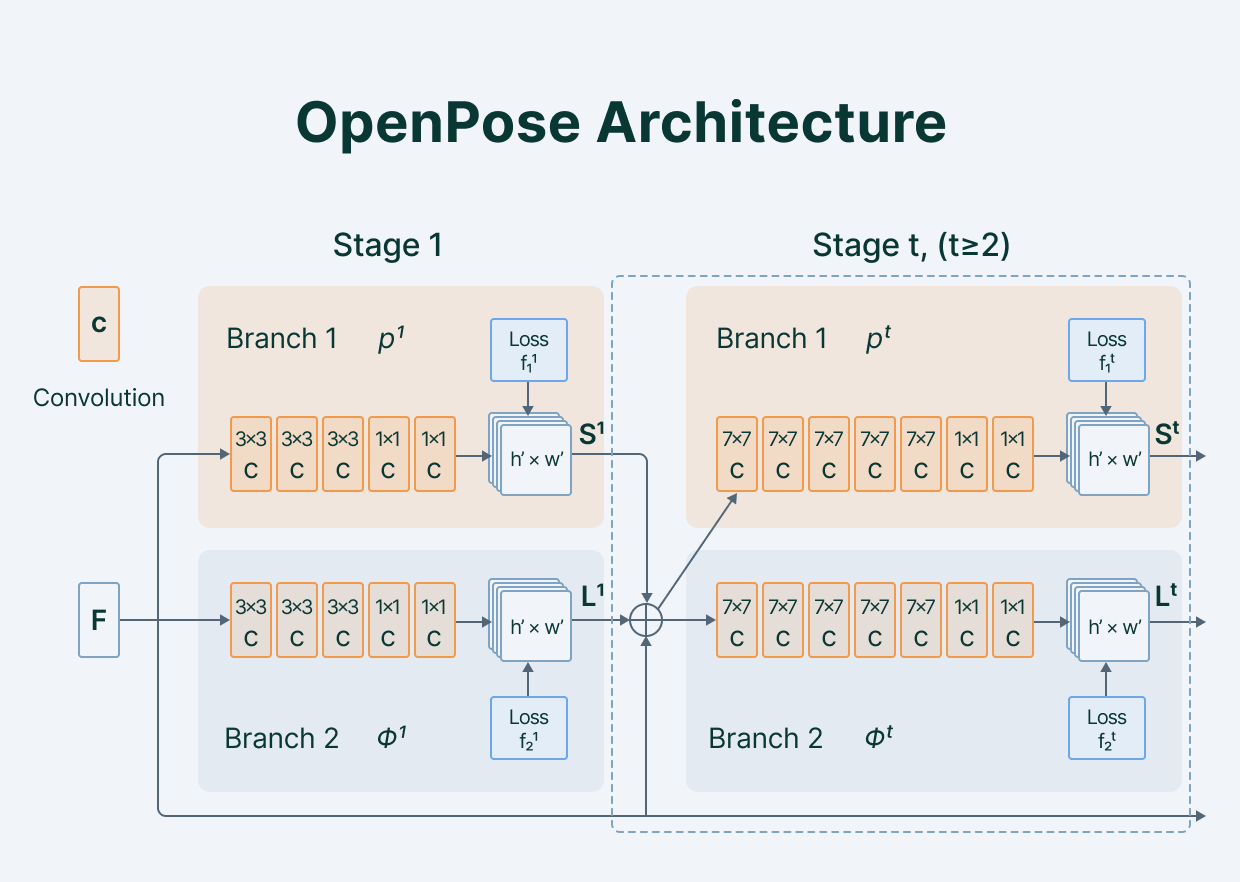
Essentially, the predictions from the two branches plus their associated features are concatenated to form a human skeleton or human skeletons based on the number of people. Successive stages of CNNs produce a refined prediction.
AlphaPose (RMPE)
Regional Multi-person Pose Estimation (RMPE) implements a top-down approach to HPE. This model is also known as Alpha-Pose Estimation. Top-down approaches to HPE are fraught with errors that result in inaccurate predictions and can be very challenging.
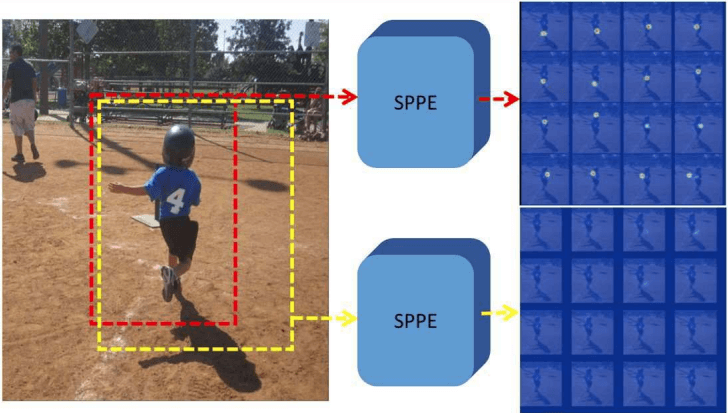
The image above shows two bounding boxes, the red box represents ground truth while the yellow represents what the computer vision algorithm thinks the correct object is.
Though the human pose cannot be estimated even with the correct bounding box in red, the yellow bounding box will be considered the “correct” one to classify human beings.
In AlphaPose, the authors address this imperfection in human detection using a 2-step framework employing two separate networks.
- Symmetric Spatial Transformer Network (SSTN) narrows the crop to the appropriate region in the input image, which simplifies the classification task and improves performance.
- Single Person Pose Estimator (SPPE) helps to extract and estimate the human pose.
AlphaPose, therefore, extracts a high-quality single-person area from an inaccurate bounding box by connecting SSTN to the SPPE. By tackling invariance, this model increases classification accuracy while providing a stable framework for HPE.
DeepCut
Leonid Pishchulin et al. proposed DeepCut, a bottom-up approach for HPE in 2016 as a way to solve both detection and pose estimation problems simultaneously. The idea was to detect all body parts in an image, label them as a head, hands, or legs, and then separate items belonging to one person.

The network uses Integral Linear Programming (ILP) modeling to implicitly group key points from the input data, creating a “skeleton” of human forms.
Mask R-CNN
Mask R-CNN is a very popular instance segmentation algorithm. The model can simultaneously classify and localize objects, creating bounding boxes around them as well as segmentation masks. This basic architecture can be easily extended to solve human pose estimation problems.

This model uses a Convolutional Neural Network (CNN) that extracts features and their representation from the given input. The extracted features are used to generate a series of possible positions for the object, which is known as region proposal network (RPN). To ensure that the extracted features are all uniformly sized, a layer called RoIAlign is used. The extracted features are passed into the network’s parallel branches to refine a proposed region of interest (RoI) and generate bounding boxes. These regions serve as inputs for segmentation masks that define those pixels which belong in an object or not.
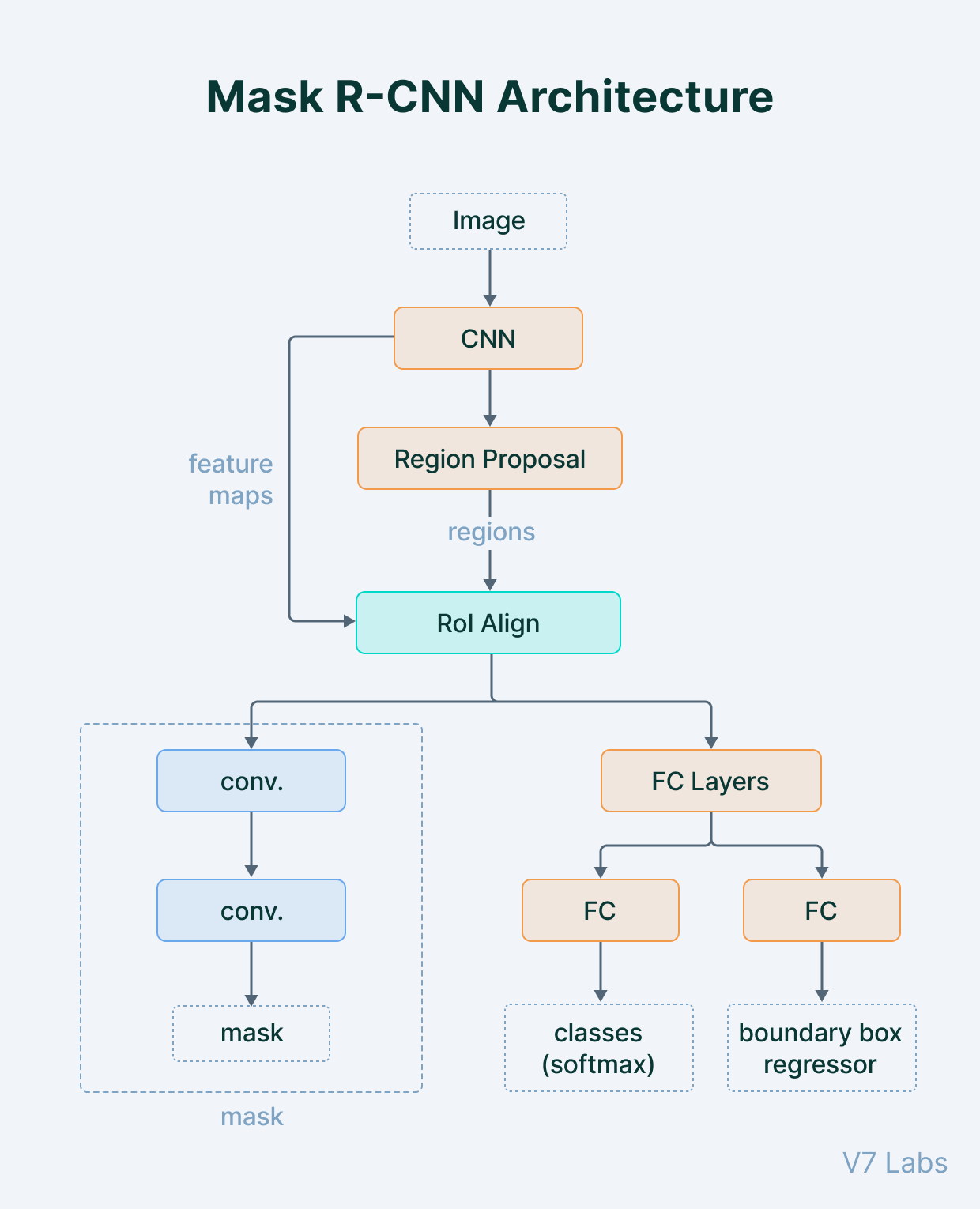
The output of the mask segmentation network can be used as a human pose detector. Because mask segmentation is very precise in object detection, it can be used to estimate the human pose quite easily. This method is similar to a top-down approach, except that person detection and part detection are performed in parallel rather than sequentially. In other words, the keypoint detection and person detection stages are two separate independent processes.
The Future of Human Pose
Human pose estimation is a very active area of research. There are many different approaches, and it’s likely that many more will emerge in the coming years. The goal of this field is to create systems that can detect a person’s pose from images or videos with high accuracy and minimal training data. The implications of advancements in HPE towards health and security are already visible with many players offering AI-based personal trainers, teletherapy, digital MSK, and virtual rehabilitation support. Modern advancements in computer technology have made it possible to create animated characters with greater ease and efficiency. For example, Microsoft’s Kinect uses IR sensors to capture human motion in real-time and render the characters’ actions virtually into gaming environments. In addition, different pose estimation architectures can also be used to capture animations for immersive video game experiences. Despite significant development of 3D human pose estimation with deep learning, some challenges and gaps between research and practical applications remain. Occlusions between body parts and between different people, inherent ambiguity, and crowded people are still being researched and need to be addressed for HPE to achieve its potential in multiple fields.
[WPSM_AC id=1869]

")